APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets


Abstract
The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to produce verifiable high-quality datasets for function-calling applications. We leverage APIGen and collect 3673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains.
Framework
This section introduces the detailed design of APIGen, an Automated Pipeline for Generating verifiable and diverse function-calling datasets. Our framework is designed with three key factors in mind: data quality, data diversity, and collection scalability. We achieve these through the key modules shown in the figure below: the multi-stage data verification process ensures data quality, the seed QA (query-answer) data sampler, API sampler, and various prompt templates ensure diversity, and our structured modular design using a unified format enables the system to scale to diverse API sources, including but not limited to Python functions and representational state transfer (REST) APIs.
Data Generation Overview
The data generation process using the APIGen framework begins by sampling one or more APIs and example query-answer (QA) pairs from the library, then formatting them into a standardized JSON format (see figure below for examples). A prompt template is selected based on the desired data generation objectives, which steers the LLM in generating relevant query-answer pairs. Each answer in the generated pairs is a function call formatted in JSON.
The adoption of a standardized JSON format for APIs, function calls, and generator outputs provides several advantages. Firstly, it establishes a structural way to verify whether the generator's output contains all necessary fields. Outputs that fail to comply with these format requirements are discarded. Secondly, the JSON structure enables efficient checking of function calls for correct parsing and validity of arguments. Calls that include arguments not present in the API library or hallucinate non-existent functions are excluded, enhancing the overall quality of the dataset. Another key benefit is the scalability it enables. With this uniform format, APIGen can easily incorporate data from diverse sources (Python functions, REST APIs, etc) by developing format converters that adapt them into these basic JSON elements, without modifying other core components, such as the prompting library, making the framework highly adaptable and extensible.
The generated function calls are subjected to a multi-stage verification process to ensure their correctness and relevance. First, a format checker verifies correct JSON formatting and parseability. Next, the API execution engine processes the calls and sends the results and queries to a semantic checker, another LLM, which assesses alignment between the function calls, execution results, and query objectives. Data points passing all stages are added back to the seed dataset as high-quality examples to enhance future generation diversity.
Multi-Stage Data Verification
Prioritizing quality is crucial, as previous research has shown that small amounts of high-quality fine-tuning data can substantially enhance model performance on domain-specific tasks. This motivates our multi-stage dataset verification process to align large language models effectively.
The key insight driving our framework design is that, unlike synthetic chat data which can be difficult to evaluate, function-calling answers can be directly executed via their corresponding APIs. This enables checking if the output API and parameters' formats are correct, if the generated API calls are executable, and if execution results match the query's intent, etc. Based on this observation, we propose a three-stage verification process:
- Stage 1: Format Checker: This stage performs sanity checks to filter out poorly formatted or incomplete data. The LLM output must strictly follow a JSON format with the "query" and "answer" fields. Additionally, the function calls are checked for correct JSON parsing and valid arguments. Generated calls whose arguments or functions are not present in the given APIs are eliminated to reduce hallucination and improve data quality.
- Stage 2: Execution Checker: Well-formatted function calls from Stage 1 are executed against the appropriate backend. Unsuccessful executions are filtered out, and fine-grained error messages are provided for failures.
- Stage 3: Semantic Checker: Successful Stage 2 execution results, available functions, and the generated query are formatted and passed to another LLM to assess if the results semantically align with the query's objective. Data points that pass all three verification stages are regarded as high-quality and added back to improve future diverse data generation.
Methods to Improve Dataset Diversity
Encouraging diversity in training datasets is crucial for developing robust function-calling agents that can handle a wide range of real-world scenarios. In APIGen, we promote data diversity through multiple perspectives, including query style diversity, sampling diversity, and API diversity.
- Query Style Diversity: APIGen's dataset is structured into four main categories: simple, multiple, parallel, and parallel multiple, each designed to challenge and enhance the model's capabilities in different usage scenarios. These categories are controlled by corresponding prompts and seed data.
- Sampling Diversity: APIGen utilizes a sampling system designed to maximize the diversity and relevance of the generated datasets. This includes API Sampler, Example Sampler, and Prompt Sampler.
In APIGen, the number of examples and APIs sampled for each dataset iteration is randomly chosen from a predefined range. This randomization enhances dataset variability by preventing repetitive patterns and ensuring a broad coverage of scenarios.
Dataset API Sources
To ensure a high-quality and diverse dataset, we focused on collecting real-world APIs that could be readily executed and came with thorough documentation. We primarily sourced APIs from ToolBench, a comprehensive tool-use dataset that includes 16,464 REST APIs across 49 coarse-grained categories from RapidAPI Hub. This hub is a leading marketplace featuring a vast array of developer-contributed APIs.
To further enhance the usability and quality of the APIs, we perform the following filtering and cleaning procedures on the ToolBench dataset:
- Data Quality Filtering: We remove APIs with incorrectly parsed documentation and those lacking required or optional parameters. APIs requiring no parameters were excluded to maintain the challenge level appropriate for our dataset needs.
- API Accessibility Testing: We tested API accessibility by making requests to each endpoint using example parameters provided in the dataset and through the Stable Toolbench server. APIs that could not be executed or returned errors, such as timeouts or invalid endpoints, were discarded.
- Docstring Regeneration: To improve the quality of API documentation, we regenerated docstrings for the APIs that have noisy and unusable descriptions.
After cleaning, we obtain 3,539 executable REST APIs with good documentation. Additionally, we incorporated Python functions as another API type, inspired by the executable evaluation categories of the Berkeley function-calling benchmark. We collected 134 well-documented Python functions covering diverse fields such as mathematics, finance, and data management. Sample API examples are provided in the supplementary material.
The original ToolBench dataset contained semantically overlapping categories such as Finance and Financial. We consolidated these into 21 distinct categories to ensure clarity and balance across the dataset. Figure illustrates the distribution of the 3,673 executable APIs across these redefined categories, spanning sectors like technology, social sciences, education, and sports. This diverse collection of APIs provides a strong foundation for synthetic data generation and is a valuable asset for ensuring data quality and reliability.
Collection Setup and Dataset Details
To validate the effectiveness of the APIGen framework, we generated datasets targeting various query styles. We utilized several base LLMs for data generation, including DeepSeek-V2-Chat (236B), DeepSeek-Coder-33B-Inst, Mixtral-8x22B-Inst, and Mixtral-8x7B-Inst. For each model, our target was to generate 40,000 data points by sampling different combinations of APIs, seed data, and prompt templates. To foster diversity in the generated responses, we set the generation temperature to 0.7 across all models. Examples of the prompt templates and APIs used are provided in the supplementary materials for reference.
Table below presents statistics for the data generation process with different models, including the total verified data point count and the number of filtered data points at each verification stage. The filtering process successfully removes many low-quality data points due to formatting issues, execution errors, or failure to pass the semantic check. The first two stages, format checker and execution checker, typically filter out the majority of low-quality data. These data points often have infeasible argument ranges, incorrect types, missing required parameters, or more severe issues such as hallucination of function calls or parameters. Our systematic verification process provides a rigorous way to reduce the occurrence of these situations.
| Model | Verified Data | Fail Format | Fail Execution | Fail Semantic | Pass Rate |
|---|---|---|---|---|---|
| DeepSeek-Coder-33B-Inst | 13,769 | 4,311 | 15,496 | 6,424 | 34.42% |
| Mixtral-8x7B-Inst | 15,385 | 3,311 | 12,341 | 7,963 | 38.46% |
| Mixtral-8x22B-Inst | 26,384 | 1,680 | 5,073 | 6,863 | 65.96% |
| DeepSeek-V2-Chat (236B) | 33,659 | 817 | 3,359 | 2,165 | 84.15% |
The semantic checker also plays a crucial role in filtering generated data that does not align with the query's objectives. For instance, if a user's query contains multiple requests, but the returned results only address one, or if the generated function-call data and execution results do not match the user's query, the data point will be filtered out. Including these data points in the training set for model training could potentially harm the performance, as demonstrated in the experiments.
We observe that stronger models like DeepSeek-V2-Chat and Mixtral-8x22B-Inst have better format-following capabilities and higher pass rates, while the two relatively smaller models have a much higher likelihood of producing data that cannot be executed. This suggests that when using weaker models to generate data, a strict verification process is recommended to filter out low-quality data.
We are releasing approximately 60,000 high-quality function-calling datasets generated from the two strongest models: Mixtral-8x22B-Inst and DeepSeek-V2-Chat (236B). These datasets include all the query styles mentioned and cover a wide range of practical situations, with 3,673 diverse APIs across 21 categories. Each data point has been verified using real-world APIs to ensure its validity and usefulness. By making this dataset publicly available, we aim to benefit the research community and facilitate future work in this area.
We mainly test our function-calling models on the Berkeley Function-Calling Leaderboard (BFCL), which offers a comprehensive evaluation framework for assessing LLMs' function-calling capabilities across various programming languages and application domains like Java, JavaScript, and Python.
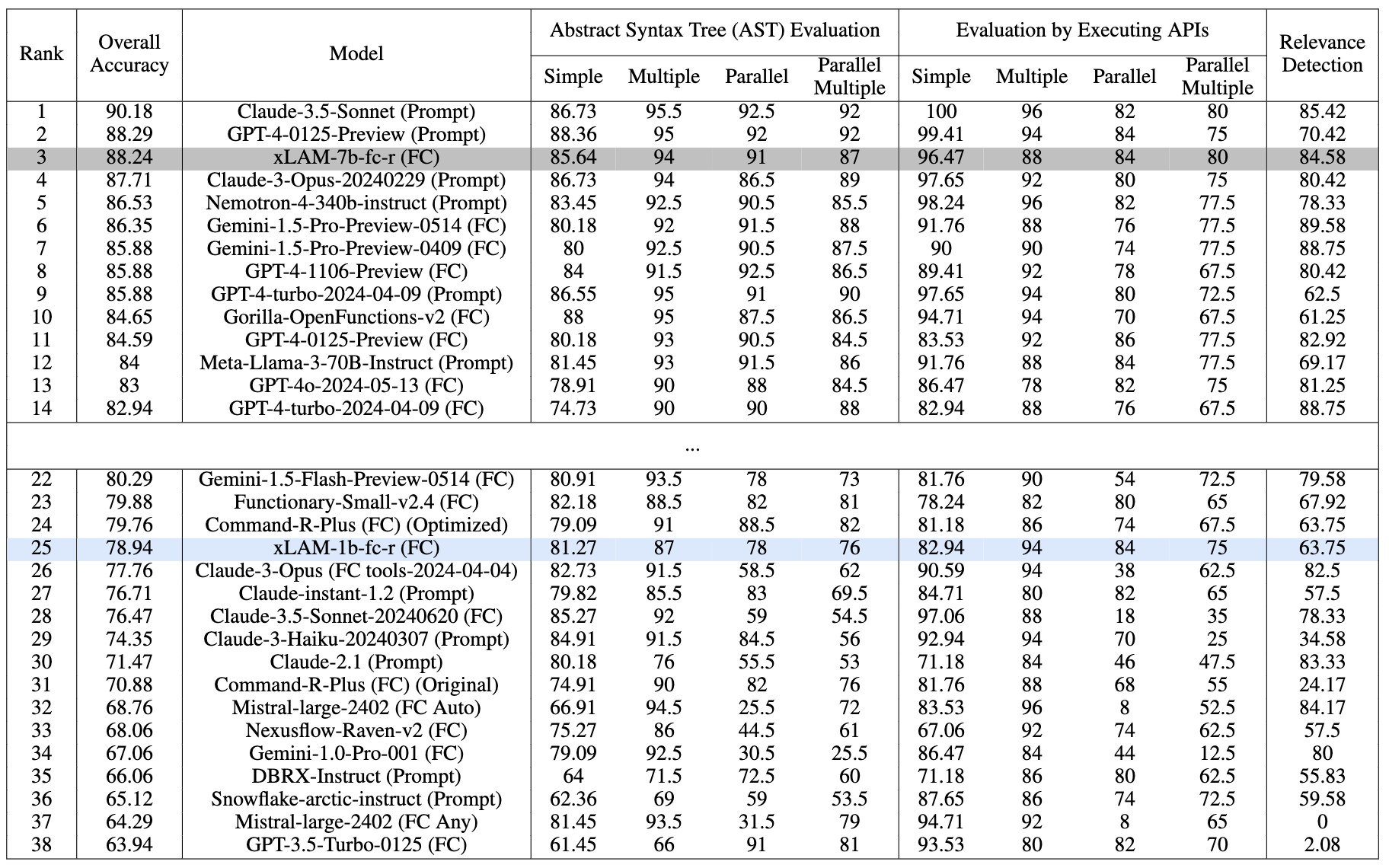
Performance comparison on the BFCL benchmark as of date 07/18/2024. Evaluated with temperature=0.001 and top_p=1
Our xLAM-7b-fc-r secures the 3rd place with an overall accuracy of 88.24% on the leaderboard, outperforming many strong models. Notably, our xLAM-1b-fc-r model is the only tiny model with less than 2B parameters on the leaderboard, but still achieves a competitive overall accuracy of 78.94%, outperforming GPT3-Turbo and many larger models. Both models exhibit balanced performance across various categories, showing their strong function-calling capabilities despite their small sizes.